0x00 前言
之前一直在思考自己的基础问题,所以在年初的时候在逛leecode的时候看到了数据结构入门,所以就跟着节奏来进行刷题
链接如下:https://leetcode-cn.com/study-plan/data-structures/?progress=vjef5is
专题主要是几个部分:数组、字符串、链表、队列、栈、树
其中树占的篇幅非常大,由于怕刷完之后过一段时间给忘记了所以提笔记录一下在刷题过程中一些比较好的思路和头绪,来进行一个复盘
0x01 时间复杂度 && 空间复杂度
时间复杂度
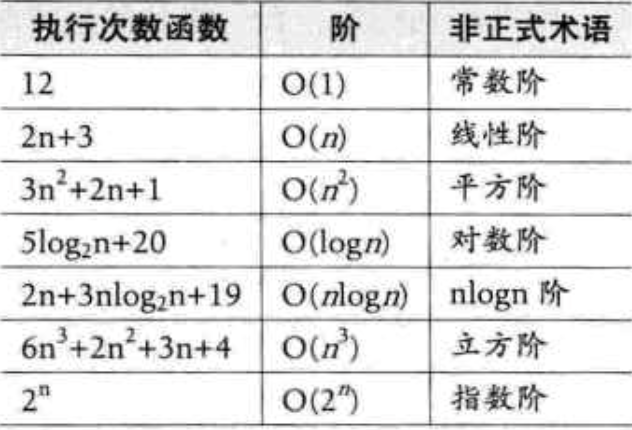
空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的一个量度,同样反映的是一个趋势,我们用 S(n) 来定义

0x02 数组
重复问题
比较常见的题目是处理重复的元素,这里有几种解决办法
-
通过将元素放到 HashSet 、HashMap 中,通过 key-value 来处理重复问题,插入数据到哈希表中的时候先进行判断是否有重复元素
// 这里利用 Set 元素不能重复的特性 Setset = new HashSet (); for (int x : nums) { if (!set.add(x)) { return true; } } return false; -
通过数组来处理即 a[val] = 1 ,如果目标存在那么对应的就为1 反之就为 0
例:111,112,111
a[111] = 1 那么在读取到 a[111] 之后发现值为1说明111为重复元素
-
如果是数值的话可以通过排序然后通过
return arr[i] == a[i+1]来判断是否重复
双指针
双指针算法有一个前提,需要两个排序的数组
大致逻辑就是两个指针分别之乡两个数组,然后进行比较将符合要求的结果放到我们最终的数组里
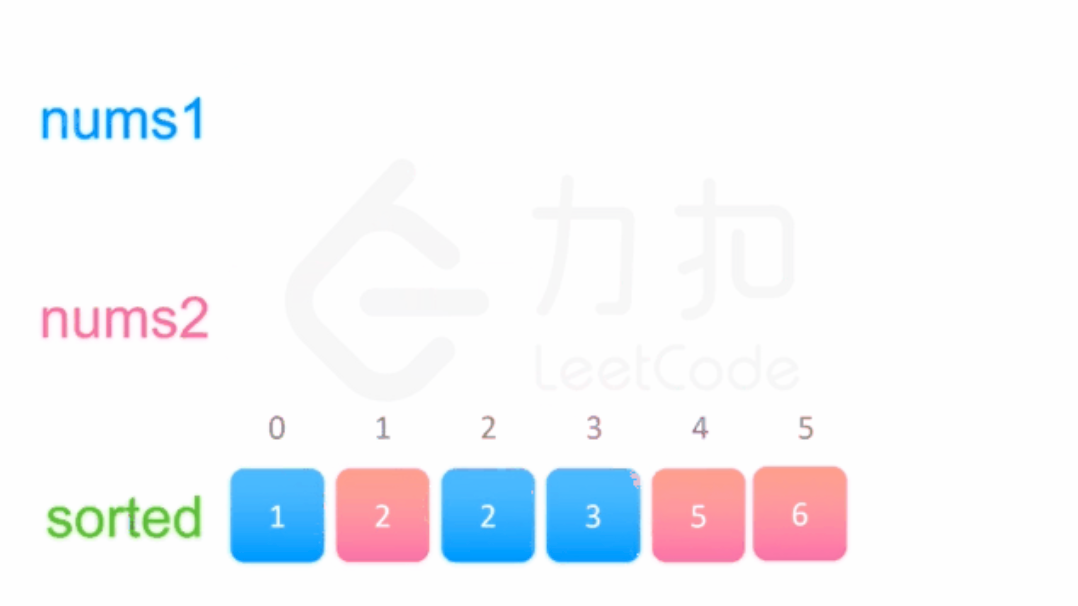
合并两个有序数组:https://leetcode-cn.com/problems/merge-sorted-array/
通过不断比较两个指针对应的值将符合要求的放到 sorted 里 ,同时也要注意指针指到数组末尾的情况
可以通过一次遍历就解决问题非常的高效
public void merge(int[] nums1, int m, int[] nums2, int n) {
int p1 = 0 , p2 = 0;
int[] sorted = new int[m+n];
int cur;
while (p1 < m || p2 < n){
if (p1 == m){
cur = nums2[p2++];
}else if (p2 == n){
cur = nums1[p1++];
}else if (nums1[p1] < nums2[p2]){
cur = nums1[p1++];
}else {
cur = nums2[p2++];
}
sorted[p1 + p2 - 1] = cur;
}
for (int number:nums1){
System.out.println(number);
}
}递归
一篇很好的关于递归的文章:https://lyl0724.github.io/2020/01/25/1/
在编写递归的过程中只需要关注三个问题,不要把自己带入到递归里面,这样会想不清楚的
- 整个递归的终止条件。
- 一级递归需要做什么?
- 应该返回给上一级的返回值是什么?
递归限制遍历深度 ,每次递归都把数据进行传入
digui(TreeNode tree,int depth)切换自身参数顺序
public int[] intersect(int[] nums1, int[] nums2) {
// 确保小的在最前面
if (nums1.length > nums2.length){
return intersect(nums2,nums1);
}0x03 字符串
重复问题
还是和之前一样的思路,我个人比较喜欢用数组来解决,可以在过程中将字符串转换成对应的 ascii 码
int cur = strings[i] - '0'0x04 链表
链表和数组的区别:数组都是连续的存储单元,链表通过 next 可以将数据做到不存储在连续的单元,链表由一系列节点组成,每个节点都由元素和指针域组成,指针域指向下一个节点,如果当前是最后一个那么指向的就是 null
public class ListNode {
int val;
ListNode next;
ListNode() {}
ListNode(int val) { this.val = val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}我个人在创建链表的时候一般会创建一个虚拟头节点
// 链表赋值/创建
// 创建两个指针一个指向虚拟头节点另一个进行移动赋值
ListNode head = new ListNode(Integer.MIN_VALUE),p=head;
int[] list = new int[]{1,2,6,3,4,5,6};
for (int num:list){
p.next = new ListNode(num);
p = p.next;
}
return head.next;
移除链表元素
遍历链表把需要的元素放到到新的链表中,如果下一个的值等于目数值那么就把下一个切换到下一个点下一个(p1.next = p1.next.next)
在遍历过程中需要通过 while 来进行确定下一个是否为 null 否则会抛出空指针异常
class Solution {
public ListNode removeElements(ListNode head, int val) {
ListNode temp = new ListNode(-1);
temp.next = head;
ListNode p1 = temp;
while (p1.next != null){
if (p1.next.val == val){
p1.next = p1.next.next;
}else {
p1 = p1.next;
}
}
return temp.next;
}
}删除链表重复元素
遍历链表来进行比较,如果当前和下一个的数值相等就把下一个节点指向下一个的下一个(前提是链表是已排序的)
class Solution {
public ListNode deleteDuplicates(ListNode head) {
ListNode p = head;
while (p != null && p.next != null){
if (p.val == p.next.val){
p.next = p.next.next;
}else {
p = p.next;
}
}
return head;
}
}判断链表是否成环
采用快慢指针的方法,即一个移动的慢一些一个快一些,如果两者相遇了那么就说明链表成环了
public class Solution {
public boolean hasCycle(ListNode head) {
ListNode slow = head,fast = head;
while (fast != null && fast.next != null){
slow = slow.next;
fast = fast.next.next;
if (slow == fast){
return true;
}
}
return false;
}
}0x05 栈 && 队列
栈
先进后出
可以判断有效的符号,即判断是否闭合,那么可以通过 HashMap 和 栈来解决
在栈中只存放左半部分的符号,遍历符号如果是左半部分就压入,如果当前值是右半部分就从栈里弹出一个,然后根据弹出的左半部分从 hashmap 中寻找如果栈为空则说明没有有效闭合多出了一个单边符号,如果栈中有元素就弹出(弹出的一定是左半部分)根据左半部分去哈希表中寻找对应的右半部分,如果和当前值相等就return true 反之为 false
HashMap<Character,Character> temp = new HashMap<>();
temp.put('(',')');
temp.put('{','}');
temp.put('[',']');
char[] chars = s.toCharArray();
Stack<Character> stack = new Stack<>();
for (char ch:chars){
if (temp.containsKey(ch)){
stack.push(ch);
}else{
if (stack.empty()){
return false;
}
char left = stack.pop();
if (!temp.get(left).equals(ch)){
return false;
}
}
}队列
先进先出
在 java 中使用 Queue
Queue<Integer> integers = new LinkedList<>();
integers.offer(1) // 入队
integers.poll() // 出队0x05 树
树是图的特殊类型,有跟节点和子节点,然后叶子节点就是没有子节点的节点
个人觉得树应用的范围比较多例如Linux的文件目录,Ast 语法树等等
树我个人觉得主要是几个部分:
-
创建
-
遍历
-
针对性修改
树节点通过遍历进行创建,我这里是递归创建,先创建树的左子节点然后再创建树的右子节点
public TreeNode createBinaryTree(Queue<Integer> queue){
if (queue.isEmpty()){
return null;
}else if (queue.peek() == -1){
queue.poll();
return null;
}
// 先把创建跟节点,然后先创建左边的 再创建右边的 最后就返回跟节点了
TreeNode root = new TreeNode(queue.poll());
root.left = createBinaryTree(queue);
root.right = createBinaryTree(queue);
return root;
}遍历就是前序遍历 、中序遍历、后序遍历
我这里是利用的递归,但是可以用栈来处理因为递归实际上就是维护了一个隐形的栈
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
res = orderTraversal(root,res);
return res;
}
public List<Integer> orderTraversal(TreeNode root,List<Integer> res){
if (root == null){
return new ArrayList<>();
}
res.add(root.val); // 位置不同对应前序遍历 、中序遍历、后序遍历
orderTraversal(root .right,res);
return res;
}// 利用栈来做
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<Integer>();
if (root == null) {
return res;
}
Deque<TreeNode> stack = new LinkedList<TreeNode>();
TreeNode node = root;
while (!stack.isEmpty() || node != null) {
while (node != null) {
res.add(node.val);
stack.push(node);
node = node.left;
}
node = stack.pop();
node = node.right;
}
return res;
}
}BST 树是二叉搜索树,二叉搜索树中,二叉搜索树的中序遍历可以变成升序数组(这个特性挺好用的)
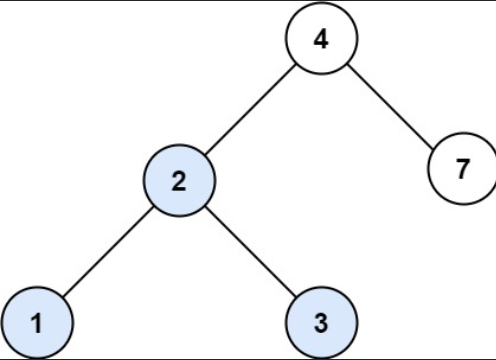
0x06 其他
递归优化
深而不广的递归通过队列来进行优化
//创建一个队列
Queen<File> queue = new LinkedList<File>();
queue.offer(file);
while(!queue.isEmpty()){//如果队列不为空
File file = queue.poll();
if(file.isDirectory()){
//从队列中获取一个File
File[] files = file.listFiles();
//是目录,将目录下所有文件遍历出来,存储到队列中
for(int i =0;i<files.length;i++)
queue.offer(files[i]);
}else{
//是文件,进行输出。
System.out.println(file.getName());
}
}动态规划
这块感觉需要多刷题,个人觉得动态规划是递归的优化版本,我们需要找到对应的递推式